STMTrack: Template-free Visual Tracking with Space-time Memory Networks

Motivation
离线训练的Siamese跟踪器已经充分完全挖掘了第一帧模板信息,但它们抵抗目标外观变化的能力依然有限。现有的模板更新机制大多依赖耗时的数值优化或复杂的手工设计策略,这阻碍了它们的实时跟踪和实际应用。本文提出了一种基于时空记忆网络的跟踪框架,该框架能够充分利用与目标相关的历史信息,从而更好地适应跟踪过程中的外观变化。这样避免了模板更新,所以叫template-free。主要创新点包括:
- 引入记忆机制存储目标的历史信息,引导跟踪器聚焦在当前帧中信息最丰富的区域;
- memory network的像素级相似度计算能够生成更精确的目标框。
运行速度37 FPS
Method

Architecture
整体框架如图2所示,主要包括三部分:特征提取网络、时空记忆网络和头部预测。特征提取网络包括绿色的记忆分支和蓝色的查询分支。记忆分支输入多个历史帧以及对应的前背景标签,查询分支输入当前帧。特征提取后,时空记忆网络从所有记忆帧中检索与目标相关的信息,生成综合特征图进行最后的分类回归。
Feature Extraction Network
对memory的每个分支,特征提取为:

$m_i$ 表示第i帧图像,$c_i$ 表示第i个前背景标签(根据gt构建的0/1 mask),$ \varphi_0^m $ 和 $g$ 将图像和标签统一到同一维度从而相加,$ h_m $ 对特征降维到512。
对于query分支:
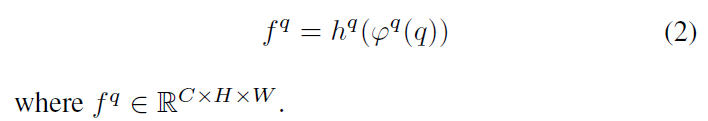
$ \varphi^m $ 和 $ \varphi^q $ 结构一样但参数不共享。
Space-time Memory Network
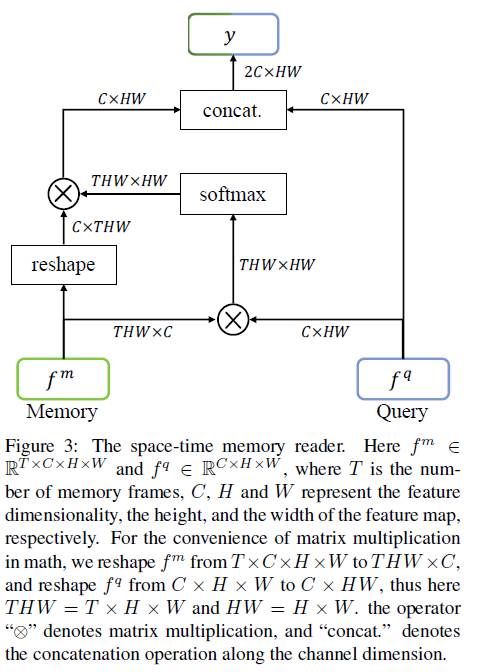
首先计算memory的 $f_m $ 和 query的 $f_q $ 每个像素之间的相似性 $\omega \in THW \times HW $

这个操作类似non-local或self-attention,相当于用query去检索历史帧中与目标相关的信息作为软权重来加权 $f_m $。最后将加权后的结果与$f_q $ 拼接起来

与non-local区别在于该方法采用相似性矩阵作为软权值从多个记忆帧中检索目标信息,而不是计算特征图中每个像素对的非局部自注意。
Head Network
常规的FCOS类预测头。
Inference Phase
训练和推理时记忆帧的数量是可以不一致的,因为不影响优化参数的数量。
推理时的记忆帧采样策略为:首先保留最可靠的第一帧和最相似的上一帧,剩下的帧数均匀采样

Experiments
Ablation Study
主要分析了是否共享backbone参数,前背景标签的作用,记忆帧的数量的影响。
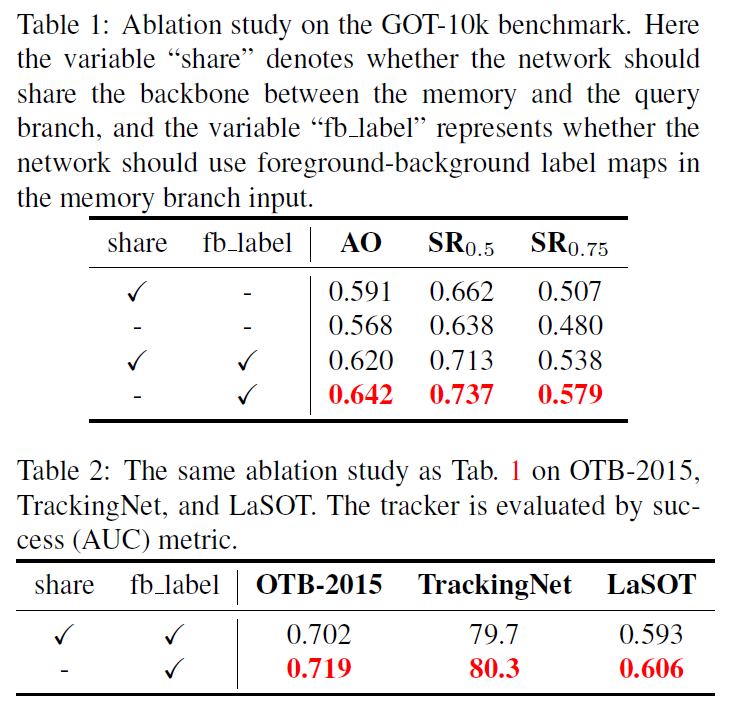
加了 fb_label 之后,不共享backbone参数效果更好。可能是因为此时两个分支的特征空间已经不一样了,期望学到的东西也是不一样的。
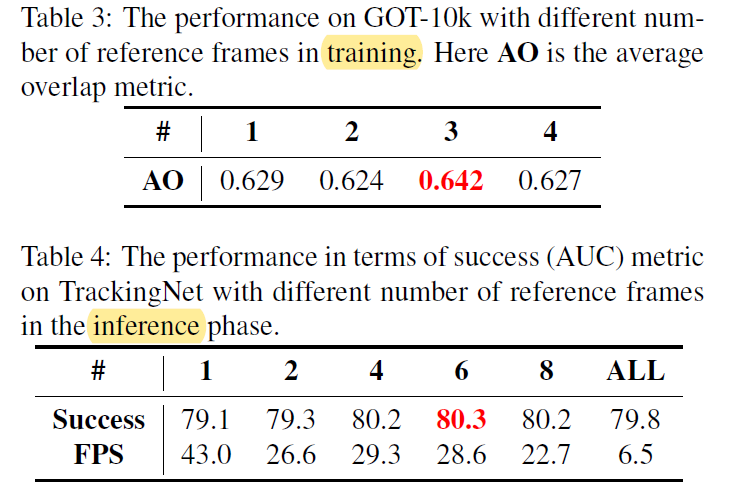
随着记忆帧的数量增加,性能都是先增后减。
训练时帧数越多,可以训练的目标模式越多,但与当前帧相似的帧也会越多。在这种情况下,网络倾向于比较最相似的图像对,而不是学习当前帧与有杂波背景或部分遮挡的帧之间的相似性。
Comparison with the stateoftheart





总结
提出了一种新的基于时空记忆网络的跟踪框架。该框架摒弃了传统的基于模板的跟踪机制,使用多个记忆帧和前背景标签映射来定位查询帧中的目标。在时空记忆网络中,通过查询帧自适应地检索存储在多个记忆帧中的目标信息,使跟踪器对目标变化具有较强的自适应能力。