Learning to Filter: Siamese Relation Network for Robust Tracking

Motivation
- Siamese跟踪器的训练设置只是在大量的图像对中匹配同一个目标,而忽略了它们之间的区别,因此对相似干扰物的判别能力不够好;
- 分类和回归是独立优化的,造成二者之间的不匹配。具体来说,分类置信度最高的位置对应的目标框可能并不是最准确的(类似检测中general focal loss等文章的观点)。
针对上述问题,作者提出了两个模块:
- Relation Detector (RD) 构造了一个2-way-1-shot的少样本学习方法来过滤干扰物。并且使用对比训练策略 (contrastive training strategy),不仅学习匹配相同的目标,而且学习如何区分不同的目标 ;
- Refinement Module (RM) 将RD和分类分支获得的信息进行整合,细化跟踪结果。RM可以联合优化分类分支和回归分支,缓解两个分支的不匹配。
Method
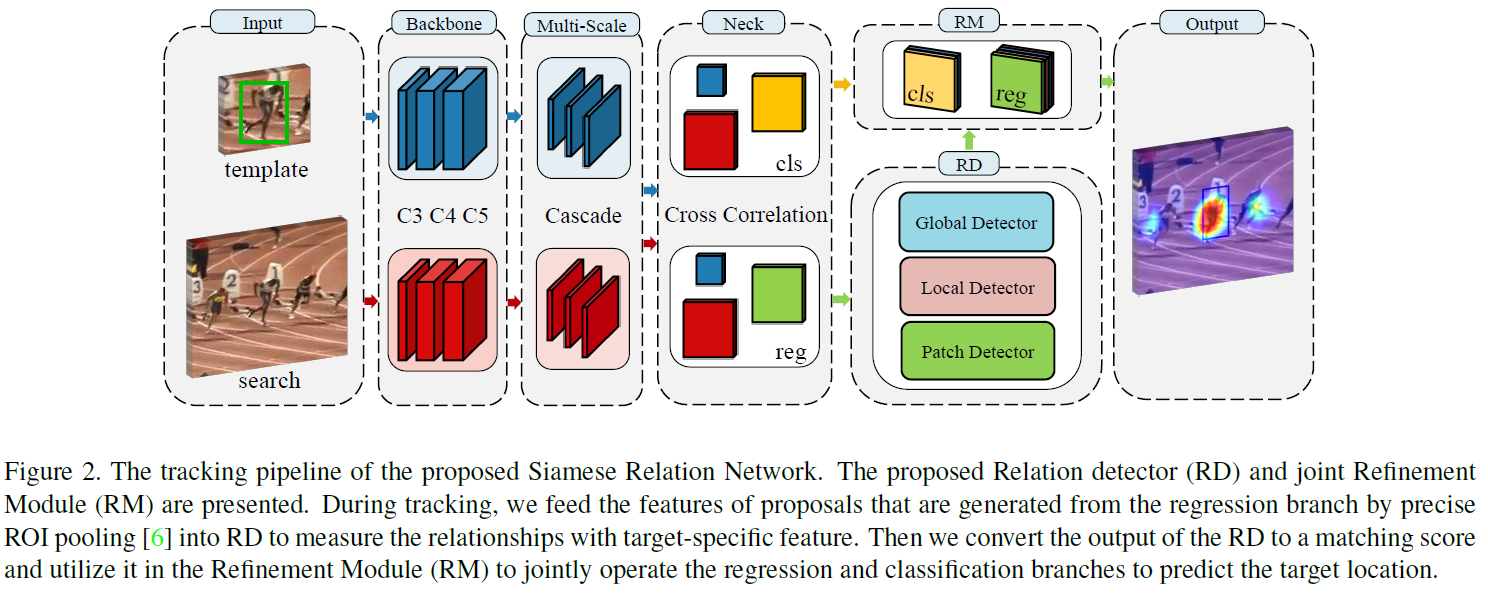
整体框架如图2,baseline是SiamBAN,经过特征提取后,将目标和回归分支生成的proposal送入RD计算它们之间的相似性(metric-based),RD输出的结果与分类分支的结果融合后得到最终的目标输出。
Relation Detector
比较目标和proposal相似性的最简单的方法就是各种线性距离(欧式距离、余弦距离等),然而面对难以分辨的干扰物时很容易失效。因此,本文提出了一种自适应的非线性比较器。该方法受启发自CVPR2020的 Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector,是一个metric-based的少样本学习方法,具体包括Global Detector, Local Detector, and Patch Detector三个模块,如图3所示。

回归分支响应图的每个位置都会预测一个框,提取其ROI特征(query),与目标模板的ROI特征(support)共同送入3个Detector中:
- Global Detector 将目标和proposal的ROI特征拼接后做全局池化,经过几层FC得到global分数;
- Local Detector 将两个ROI特征做DW-Corr得到local分数;
- Patch Detector 将两个ROI特征拼接后经过若干卷积得到patch分数。
最后将三个得分加起来就得到最终的匹配相似性分数,该分数能够同时考虑全局、局部以及patch之间的关系。
Contrastive Training Strategy
RD的训练是一个2-way-1-shot的少样本学习过程,2-way表示目标和非目标两类。在训练RD时,作者不仅对属于目标类别的物体进行匹配,还对非目标类别的干扰物进行区分。因此构建一个三元组训练集 $(s_c, q_c, s_n)$,其中$s_c$和$s_n$分别表示positive support图像和negative support图像,$q_c$是query图像。$s_c, q_c$取自同一个视频,而$s_n$取自其他视频(表示干扰物)。通过输入的三元组图像可以生成不同的样本组合,定义$s_p$为positive support的gt,$p_p$表示positive proposal,$n_n$表示negative support的gt,$p_n$表示negative proposal,将它们结合可以得到不同的样本对 $(s_p, p_p), (s_p, p_n), (n_n, p_p / p_n)$(这些样本对就是图3中输入的support和query),其比例为1: 2: 1。
在训练初期,应用简单样本可以使模型稳定收敛。为了进一步增强模型的判别能力,在训练中后期引入难样本挖掘,包括离线和在线两种方式。在线就是从IOU小于0.2的proposal中选择得分最高的作为难负样本;离线就是像SiamRCNN一样构建索引表,从中选取在嵌入空间中的最接近的难样本。
Refinement Module
分类和回归的独立优化导致分类得分最高的位置对应的框不一定是最准确的,甚至可能都不是目标,因此作者通过将RD嵌入孪生框架使得分类和回归的学习能够统一。具体来说,首先将RD的输出转换成$25 \times 25 \times 1$的匹配分数图,这个输出就反映了每个位置预测框内的物体与目标之间的相似性;将其作为权重与分类分支的分数图进行元素点乘,可以过滤掉背景中的干扰;最后将refine后的分数图经过一层卷积得到最后的分类得分,并获取最大响应位置对应的预测框。图4展示了一些响应图可视化结果,可以看到,RM将回归分支和分类分支的信息结合起来预测目标位置,从而缓解了不匹配的问题。

Ground-truth and Loss function
大部分都和SiamBAN一样,增加的RD模块采用MSE loss
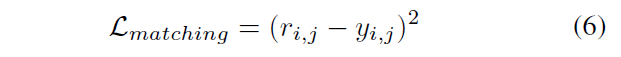
其中$r_{i,j}$表示位置$(i,j)$处的relation score;$y_{i,j}$是对应标签,上文提及的三种样本对中,$(s_p, p_p)$标签为1,$(s_p, p_n), (n_n, p_p / p_n)$标签为0。
Training and Inference
训练首先从来自同一个序列的模板和搜索区域中选择16个正样本和48个负样本来训练分类和回归分支,然后再加入另一个序列中的搜索图像(负例)用于生成RD的训练样本。第5个epoch开始在线难样本挖掘,第15个epoch开始离线难样本挖掘。整个网络端到端训练不需要fine-tune。
推理阶段第一帧先提取模板特征并通过precise ROI pooling提取ROI特征。后续帧对回归分支每个位置的输出生成proposal,提取proposal的ROI特征与模板ROI特征共同送入RD计算它们之间的关系,最后将RD的输出与分类分支的输出送入RM得到最终结果。
Experiments
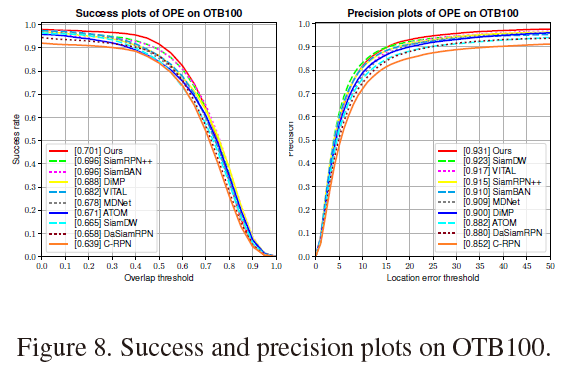
Comparison with the state-of-the-art




Ablation Study
比较了多尺度预测和使用不同组合的Relation Head的结果。
