DeepMix: Online Auto Data Augmentation for Robust Visual Object Tracking

Motivation
- 通过历史帧样本在线更新目标模型对跟踪具有重要意义。最近的研究主要集中在构建有效的更新方法,而忽略了用于学习判别模型的训练样本;
- 本文提出DeepMix,对历史帧样本的特征进行在线增广,从而强化模型的在线更新能力。具体包括通过object-aware filtering在线增强历史样本,以及通过离线训练的MixNet混合多个样本进行数据增强;
- 最后通过三个典型的跟踪器DiMP, DSiam和SiamRPN++验证提出的方法。
Method
首先点明数据增广对于提升模型判别能力非常重要,因此可以利用数据增广给现有的模型更新方法增加有效的训练样本。用公式表达如下:

其中$X_t$表示原始训练样本,$T$表示各种增广方法,$\hat {X_t}$表示增强后的样本。而现有的不管是传统还是深度学习的增广方法都不能直接适应跟踪的在线数据增强,主要包括两个原因:
- 现有方法都是sample-level的,即会生成新的样本,对这些新样本需要额外花费大量时间提取它们的深度特征;
- 现有方法都是基于退化因素(例如,噪声、模糊、雾、雨等),这些退化因素会破坏原始样本,降低模型判别力。
为了解决上述问题,作者提出要对训练样本的特征(embedding)进行增强。具体来说,首先提取样本$X_t$的特征embedding得到$\{\varphi(I_i) \in \mathbb{R}^{C \times W \times H} | I_i \in X_t\}$,然后将所有embedding拼接起来得到特征张量 $X_t \in \mathbb{R}^{N \times C \times W \times H} $,N是训练样本数量。之后把$X_t$通过数据增强映射到一个新的特征$\hat{X_t} \in \mathbb{R}^{K \times C \times W \times H} $ 送入更新模块以生成目标模型。
在特征上进行增强比直接在样本上增强更加高效,此外,作者在混合样本特征时加入了对应跟踪结果的指导。从直观上看,在视频采集过程中,感兴趣的物体可能位于场景中的任何位置,将物体放置在可能的背景区域中来增加训练样本是合理的。因此,作者根据跟踪框将样本分为目标区域和背景区域,并把它们混合以生成新样本。

其中 $M_o \in \mathbb{R}^{K \times C \times W \times H} $(此处作者笔误,第一个维度为K而不是N,已向作者求证)是二值掩膜,1表示目标区域,0表示背景区域。$W_{ \{o \ or \ b\} } \in \mathbb{R}^{K \times N \times 3 \times 3} $表示卷积,K是输出样本的个数。这个卷积的目的就是混合N个原始样本生成K个新样本,其中$W_o$和$W_b$分别负责混合目标和背景区域。下一步就需要考虑如何计算$W_o$和$W_b$,作者设计了MixNet,如图2所示。
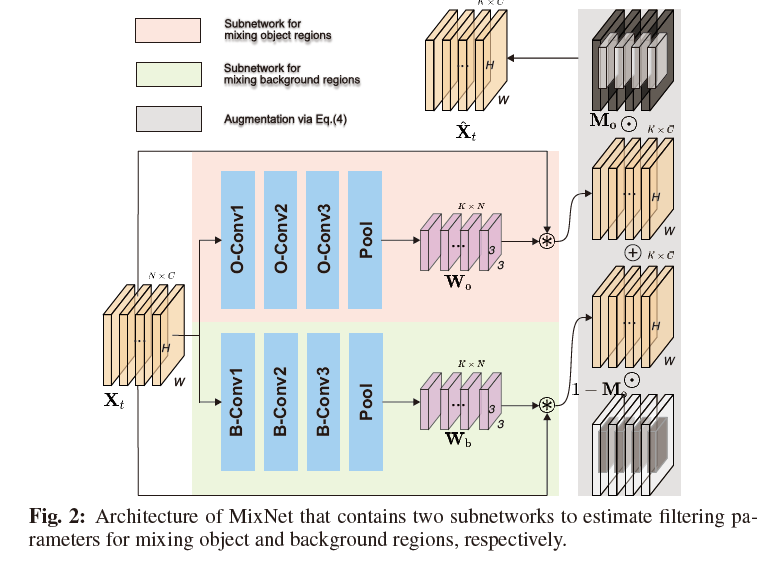
输入$X_t$,通过两个结构一致参数不同的卷积分支生成kernel $W_o$和$W_b$。这个网络可以预先离线训练好,在线跟踪时只需一次前向传播就可以高效地获得增强样本。
Implementation for SOTA Trackers
为了验证DeepMix的效果,作者在SiamRPN++, DSiam和DiMP三个跟踪器上进行实验。将原始样本$X_t$和增强样本$\hat {X_t}$相加后 ($\alpha_1 \hat {X_t} + \alpha_2 X_t$) 送入更新模块,$\alpha_1=0.05, \alpha_2=0.8$。注意 不是直接用生成的新样本替换原始样本,而是将两者进行混合。
对于SiamRPN++和DSiam,将历史N=15帧样本混合成K=1个新样本,注意SiamRPN++虽然并没有更新模块,但是MixNet也可以混合历史样本输出一个更干净的搜索特征从而促进跟踪。而在训练时,将搜索图像随机增广成15个样本送入MixNet生成1个新样本与原始图像混合后输入到之后的模块。论文这里作者笔误写成了对模板进行增广,已向作者求证。
对于DiMP,则将历史N=50帧样本混合成K=N个新样本。同样将MixNet嵌入DiMP的训练中,为了与测试保持一致,将训练过程中的3个样本改成了50个。
这里额外提一下关于生成样本的mask $M_o \in \mathbb{R}^{K \times C \times W \times H} $如何设置。对于SiamRPN++,K=1,mask根据上一帧的跟踪结果设置;对于DiMP,K=N,mask就直接根据这N帧跟踪结果设置。
Experiments
State-of-the-art Comparison

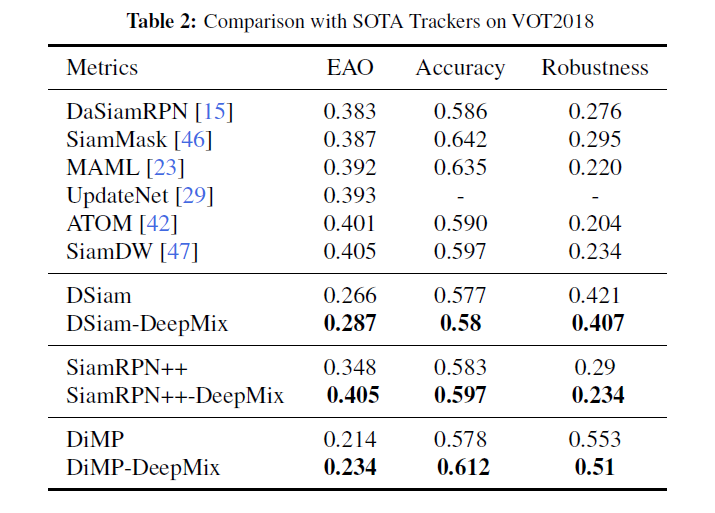
尽管baseline比原始论文得到的要低一些,但是加入了DeepMix性能依然明显提升。
Ablation study

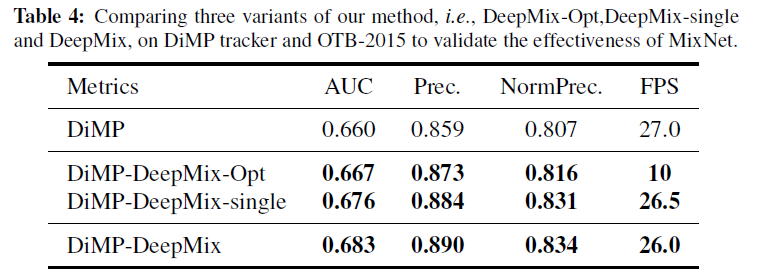
表3中DeepMix在ResNet18的提升比ResNet50大,可能是因为更强大的网络对于增广的依赖更小。
表4比较了DeepMix几种不同的实现方法,-Opt表示通过梯度下降在线优化目标函数来取代所提出的MixNet,-single表示不区分目标和模板区域只用一个分支生成新样本。
小结
这篇工作的切入点挺新奇的,以往的模型更新都在考虑如何设计更新方法,而本文则关注样本本身,从在线数据增广的角度切入,将历史样本混合生成新的样本用于模型更新。本文灵感应该还是来自于Mix类的增广方法,那是不是意味着我们可以把其他数据增广的方法也运用进来,刚好我最近也在思考类似的问题,本文可以给到一定的启发。