Domain Adaptive SiamRPN++ for Object Tracking in the Wild

Motivation
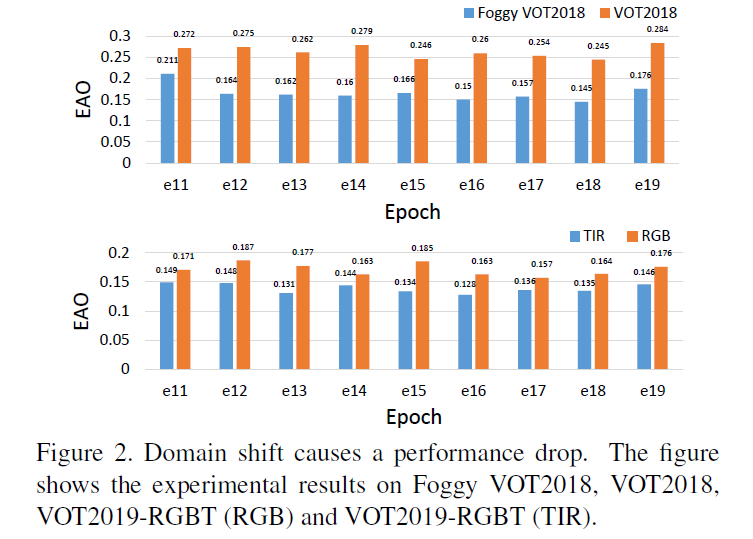
基于孪生网络的跟踪算法均假定训练和测试数据遵循相同的分布,然而在正常图像上训练的跟踪器并不能保证在其他领域的数据上(如雨雾天气的序列)也表现良好,即存在域偏移(domain shift)问题,如图1和图2。作者称本文是首次将域分布差异问题引入视觉跟踪领域。
针对这一问题,本文提出一种域自适应方法,包括Pixel Domain Adaptation (PDA) 和 Semantic Domain Adaptation (SDA)。PDA分别对(不同域的)模板和搜索图像的特征对齐,消除天气、光照等引起的像素级域偏移;SDA将(不同域的)跟踪目标的特征表达对齐,以消除语义级的域偏移。二者均通过对抗训练的方式学习域分类器,域分类器强制网络学习域不变的特征表达,从而实现域自适应。
最后作者在有雾和红外序列两个不同域的数据集上进行了验证。

Theoretical Preliminaries
最简单粗暴的方法就是搜集许多具有不同域的标注训练数据,但这显然不现实。因此我们的目标是针对无监督域自适应场景(即源域有标记而目标域未标记),使跟踪器在源域和目标域上都表现良好,而不需要额外的标注成本。一种通用的方案就是学习域不变(domain-invariant)的特征表达来缩小不同域之间的差异。作者利用 A-distance理论和概率分析来实现这一目的,下面先简单介绍这些概念。
A-distance
给定源域 $S$ 和目标域 $T$, A-distance可以用于衡量两个域样本分布的差异,定义如下:

其中h表示域分类器,$h(x)\rightarrow 0$表示样本x属于源域,$h(x)\rightarrow 1$表示样本x属于目标域。$min \ error(h(x))$表示理想域分类器的预测误差,显然,误差越小(越容易区分)表示域差异越大。现在要最小化域差异$d_A(S,T)$以实现特征对齐,等价于要最大化理想域分类器误差,即
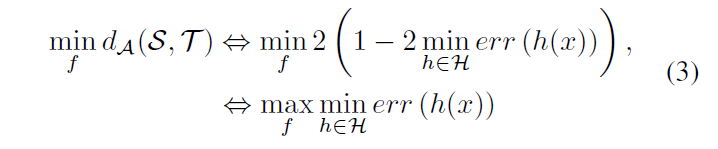
其中 f 表示样本 x 的特征表达。公式(3)是特征提取器 f 和域分类器 h 之间的minimax优化问题。这个怎么理解呢?其实类似GAN,域分类器 h 需要尽可能区分不同域的样本,而特征提取 f 需要欺骗分类器让其难以区分不同域,即让 f 提取到域不变特征。
作者在优化这个问题时采用 Gradient Reversed Layer (GRL),如下图所示,在梯度从域分类器传到特征提取之前将其取负号反转,希望粉色部分的参数向$L_d$减小的方向优化,绿色部分的参数向$L_d$增大的方向优化,用一个网络一个优化器就实现了两部分有不一样的优化目标,形成对抗的关系。(参考Gradient Reversal Layer指什么? - Just4Fan的回答 - 知乎 )

Probabilistic Analysis for Object Tracker
作者将跟踪问题看成一个后验概率 $P(S,B|Z,X)$,即给定模板Z和搜索区域X,预测分类得分S和目标框B。由于域偏移的存在,源域的联合概率分布$P_S(S,B,Z,X)$与目标域的联合概率分布$P_T(S,B,Z,X)$是不同的。
Pixel Domain Adaptation 根据贝叶斯公式,可以将联合概率分布分解成:

其中$i \in \{S,T\}$。条件概率$P(S,B|Z,X)$相当于跟踪器的分类回归分支,我们假设这部分对于不同域是一样,那么域偏移主要来自模板和搜索图像的特征提取$P(Z,X)$。为了消除域偏移,需要另Siamese网络提取域不变的特征映射,即$P_S(Z,X) = P_T(Z,X)$
Semantic Domain Adaptation 上面PDA解决天气或光照引起的全局域偏移,但不同域的目标还存在外观和类别的变化,因此还需要考虑目标语义的域偏移。类似的,可以将联合概率分解成:

同样假设条件概率$P(S | B,Z,X)$对于不同域是一样的,那么域偏移主要来自$P(B,Z,X)$。为了消除偏移,需要$P_S(B,Z,X) = P_T(B,Z,X)$,表示给定了模板、搜索区域以及对应的目标框,跟踪目标的特征表达要是一样的。考虑到目标域是没有真实框标注的,因此这里统一采用RPN的预测框表示B。
Method

图3是整体方法框架,根据上一节的A-distance理论以及概率分析,作者提出了PDA和SDA两个模块。其中PDA针对的是孪生网络的整体特征,SDA针对的是预测框内的目标特征。
Pixel Domain Adaptation
PDA包括模板对齐和搜索区域对齐,目的是通过域分类器和Siamese网络之间的minimax优化来混淆跨域的特征映射。域分类器由Conv+MaxPool+FC组成,FC层对每个像素进行二值分类,损失函数为:

m,n为像素位置,D是标签,p是预测结果。然后按照公式3的minimax优化,需要对域分类器参数最小化该损失,对siamese特征提取参数最大化该损失,即
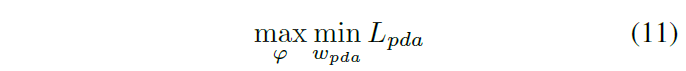
$\omega_{pda}$表示PDA域分类器参数,$\varphi$表示孪生网络参数。域分类器的参数更新方向与减少域分类损失的方向相同,这与普通的训练方法相同;而Siamese网络的参数更新方向被反转(GRL),这正是增加域分类损失的方向,二者形成对抗。
Semantic Domain Adaptation
由于不同域的类别、视角和姿态的变化,跟踪目标会发生明显的变化,SDA强制跟踪目标的特征表示在语义上是域不变的。具体过程为,通过ROI Align提取预测框内的multi-layer的ROI特征,域分类器(两层FC)对其进行分类,GRL放在域分类器和ROI Align之间。域分类损失为:

同样以对抗的方式训练SDA

$\omega_{sda}$表示SDA域分类器参数,$\varphi$表示孪生网络参数。无论跟踪目标来自源域还是目标域,目标的域不变特征都能在分数图中获得较高的响应。
最后总的训练损失包括孪生跟踪器的损失和域自适应损失

Experiments
训练时使用LaSOT作为源域数据,Foggy GOT-10k和LSOTB-TIR作为目标域数据。Foggy GOT-10k是作者生成的有雾数据集,LSOTB-TIR是红外数据集,注意二者作为目标域数据训练时是没有标注的。模板和搜索图像的裁剪通过运行现有的SiamRPN++对目标域数据集获取伪标签得到的。
表1-4展示了正常天气到有雾的跨域和RGB到红外的跨域的跟踪结果。这里的比较方式有点迷,作者列出每个epoch的结果证明性能的提升,但如果只关注最好的结果发现的性能提升其实不明显。比如Foggy VOT2018 0.211 v.s. 0.218,LSOTB-TIR 0.543 v.s. 0.547。




消融实验也呈现一样的结果,如果只比较最好的性能,单独的PDA和SDA甚至不如baseline。

其他的一些可视化结果。图6将特征压缩到平面证明了源域和目标域的特征混淆在一起,证明了域不变特征。图7证明了提出的方法在跨域性能表现良好的同时,不会损失在源域上的性能。


