Siamese Transformer Pyramid Networks for Real-Time UAV Tracking

Motivation
本文着眼于移动平台的无人机目标跟踪,融合了CNN和Transformer的优点。具体来说,通过轻量的shufflenet v2来构建特征金字塔,并使用Transformer对其进行强化(特征融合),以构建一个鲁棒的目标外观模型。开发了一种具有横向交叉注意力的集中式架构,用于构建增强的高级特征图。此外,作者设计了pooling attention module减少key和value的数量进一步降低了Transformer的内存消耗和时间复杂度。提出的方法在CPU端运行速度可超过30 FPS。

Method
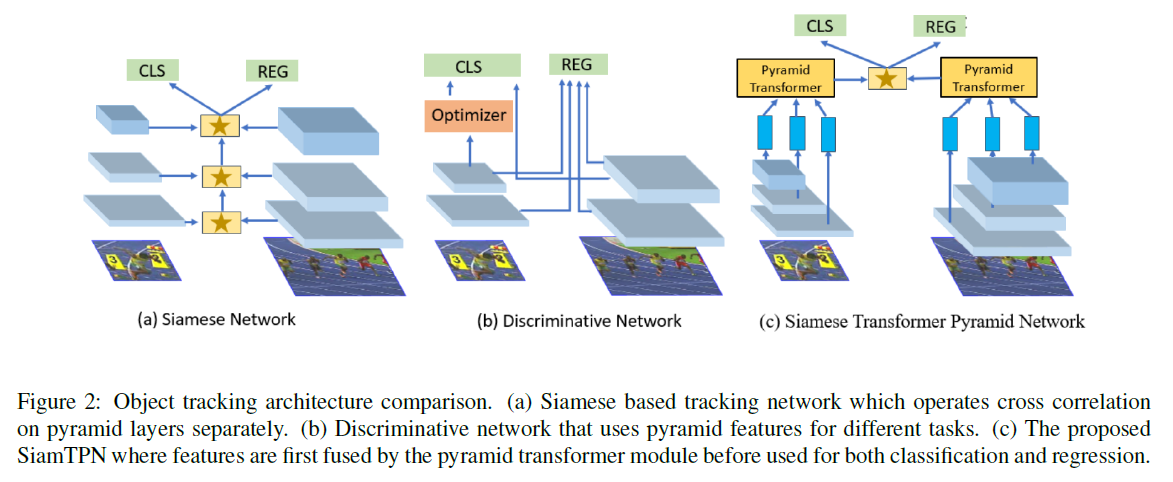
图2c为本文提出的框架,注意作者没有直接迁移复杂的transformer编码器和解码器结构,而是利用编码器设计了基于注意力的特征金字塔融合网络来更有效地学习target-specific的模型。下面分别介绍各个模块。
Feature Extraction Network
特征提取网络输出stage 3,4,5降采样倍数分别为8,16,32倍的特征,然后将模板和搜索特征分别送入Transformer Pyramid Network(TPN)进行特征融合,将融合后的特征进行互相关。
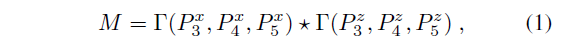
其中,$\Gamma$表示TPN模块,M表示互相关结果。
Feature Fusion Network
Multi-head Attention 经典的MHA公式如下:

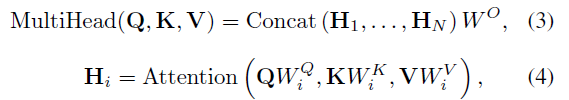
Pooling Attention MHA的计算量如下

降低计算量的方法有三种:(1)减少query的数量,(2)减少维度C,(3)减少key和value数量。(1)和(2)都会减少输入到后续预测头的特征维度(包括空间和通道),影响跟踪精度。因此我们选择(3),通过池化操作来降低K和V的空间尺寸。
为了进一步降低计算量,作者去掉了位置编码,原因包括:1)输入token的排列会受到最终互相关的约束;2)位置编码会占用额外的计算和存储资源。最终的pooling attention block(PAB)可以写成

图3对比了PAB和传统MHA的区别

Transformer Pyramid Network
为了利用同时具有低级信息和高级语义的特征金字塔,作者提出Transformer Pyramid Network (TPN)来构建具有高级语义的混合特征。TPN如图4所示,输入特征金字塔$\{P_3, P_4, P_5\}$,输出融合特征$\{P_3’, P_4’, P_5’\}$,中间包含若干个TPN block。

TPN block使用$P_4$作为所有特征层次的query,产生3个具有不同池化尺度的组合,这些组合由3个并行的PAB模块处理。其中$P_3, P_4, P_5$的池化尺寸分别为4,2,1(图4中似乎标反了)。三个尺度的输出直接相加然后送入两个自注意力的PAB中,得到最终的语义特征。整个过程用公式表示:

$P_3, P_5$直接恒等映射,以减少计算开销。PA block可以有效地提高层次特征之间的相关性。TPN Block重复B次,生成的特征用于后续互相关。预测头部分就是简单的无锚框分类回归结构,分类损失为交叉熵,回归损失为GIOU loss和L1 loss。
Experiments
实现细节上,搜索特征和模板大小分别为256和80,是目标大小的4倍和1.5倍,对应的特征金字塔尺寸为$\{h_3^x=32, h_4^x=16, h_5^x=8 \}$, $\{h_3^z=10, h_4^z=5, h_5^z=3 \}$。
Ablation Study



Attention可视化。图6中的第二、三列对比了有无TPN的响应映射。如果没有TPN来学习区分特征,相关结果将变得分散,并且更容易漂移到干扰项。最后三列说明了金字塔特征之间的注意力图。低层级(P3到P4,P4到P4)之间的注意力在整个搜索区域提取了更多的局部信息,而高层级(P5到P4)的注意力更集中在目标的语义上。
SOTA Comparison
表3中shufflenet版本的速度在CPU上达到32.1 FPS,alexnet版本在gpu上速度105FPS,且精度超过了使用resnet50的SiamRPN++和HiFT。



最后作者在真实场景中进行测试,不是很了解就不介绍了,感兴趣可以阅读原文。