轻量化目标跟踪
引言
近些年的目标跟踪算法都在往做大做强的方向发展,比如更深的网络和更复杂的模块。尽管性能越刷越高,但是却很少考虑效率问题,以至于几乎无法在边缘设备上实时运行部署,实用性较低,因此研究轻量化的目标跟踪算法是非常必要的(另外一个原因也可能是做大做强上能水论文的点越来越不好找了 /狗头保命)。本篇博客总结了三篇最近研究跟踪模型轻量化的工作。
- LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search
- Efficient Visual Tracking with Exemplar Transformers
- FEAR: Fast, Efficient, Accurate and Robust Visual Tracker
LightTrack

详细解读:【极市直播】严彬:CVPR 2021-LightTrack:基于网络结构搜索的超轻量级跟踪模型设计
LightTrack使用神经架构搜索(NAS)来设计更轻量级和高效的目标追踪器。实验表明,LightTrack与手工设计的 SOTA 跟踪器(如SiamRPN++和Ocean)相比,可以实现更优越的性能,而需要的计算量和参数要少得多。此外,当部署在资源受限的移动芯片上时,也能以更快的速度运行。
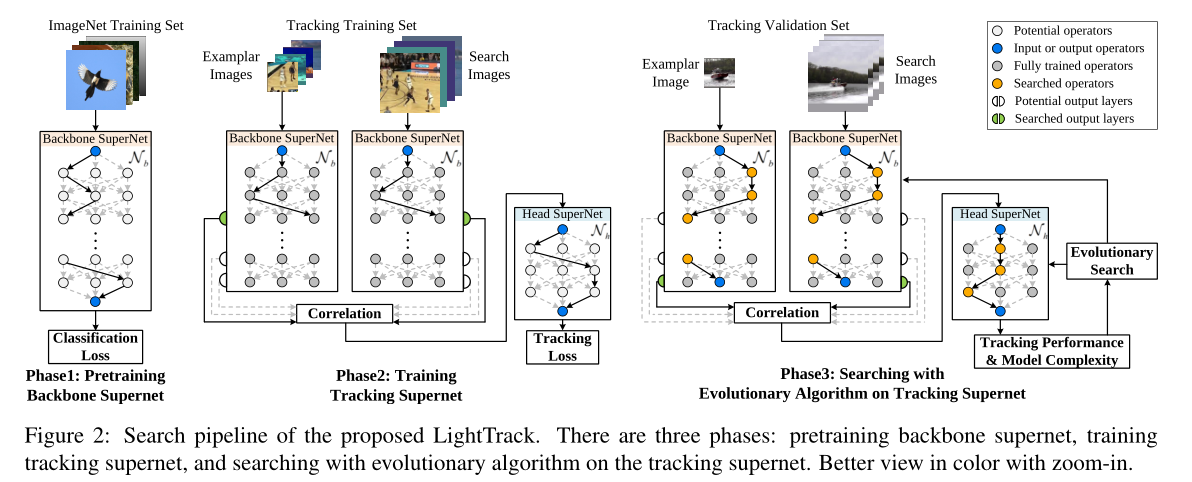
LightTrack采用one-shot NAS的方法搜索结构,流程如图2所示。整个过程训练与搜索是解耦的,首先训练超网(随机采样路径进行训练),然后用进化算法从超网中寻找最优子结构。
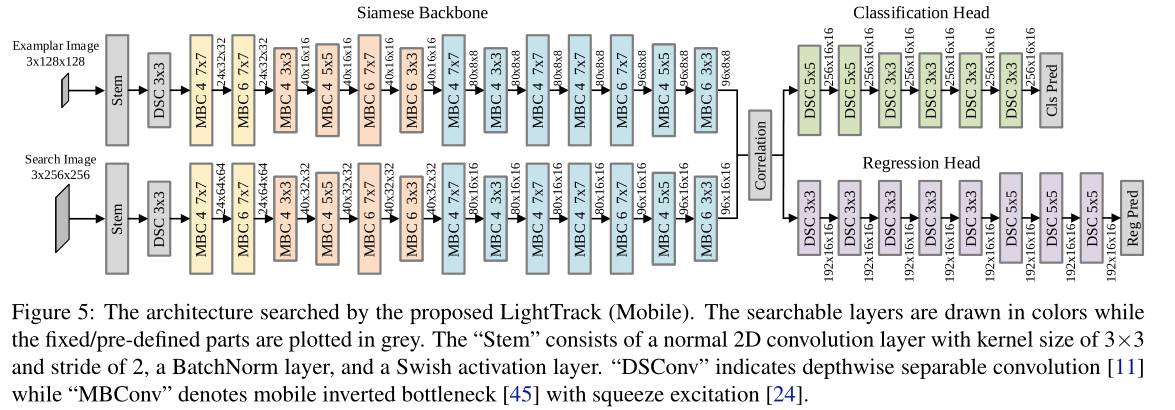
最后搜索到的LightTrack-Mobile结构如图3所示,具有如下特点:
- backbone中有将近一半使用$7 \times 7$的卷积核大小,可能是因为这样能在较浅的backbone中尽量提升感受野;
- 搜索架构选择了倒数第二个block作为特征输出,可能是因为跟踪网络并不倾向太高级的语义特征;
- 分类分支需要的网络层数比回归分支要少,可能是因为粗目标定位比精确的边框回归更容易。
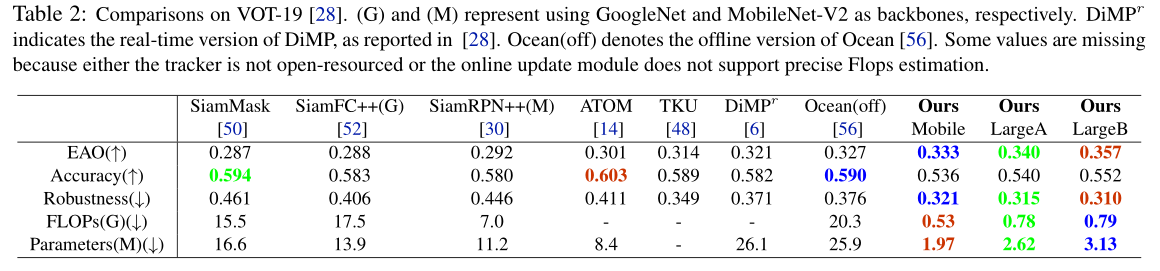
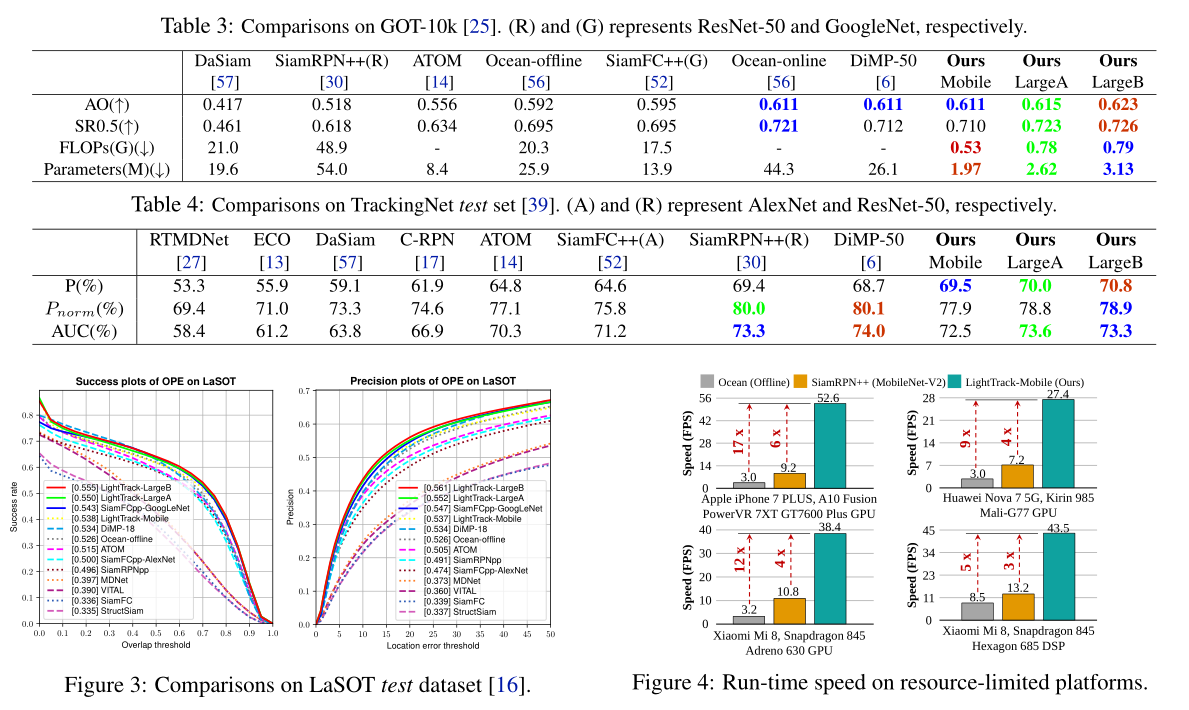
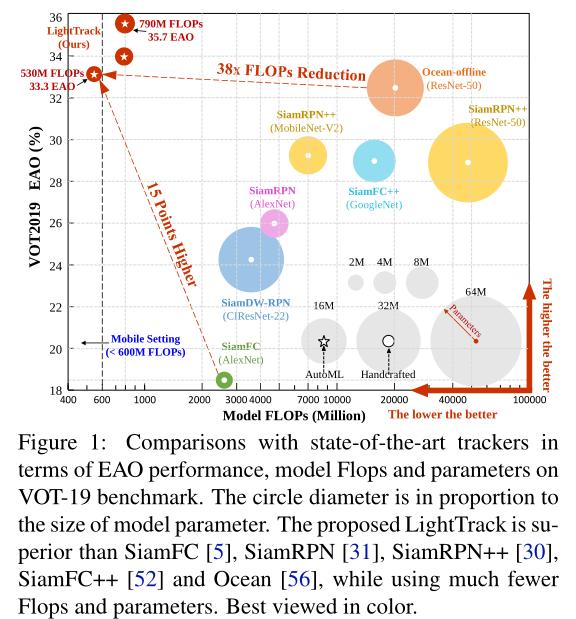
实验可以看到三个版本mobile,largeA,largeB在性能、计算量和参数量上都具有优势。在骁龙845中,LightTrack运行速度比Ocean快12倍,参数量减少13倍,计算量减少38倍。作者称这种改进可能会缩小学术模型和工业部署在物体跟踪任务中的差距。
Exemplar Transformer

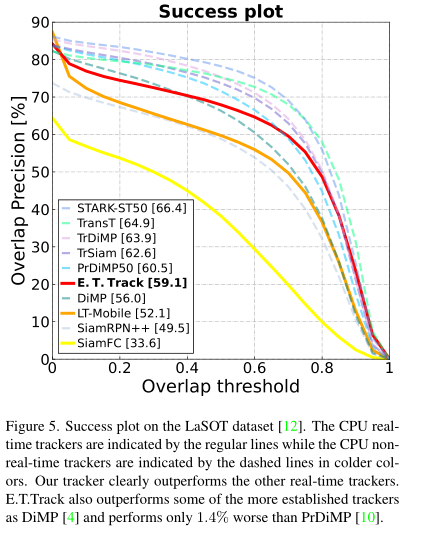
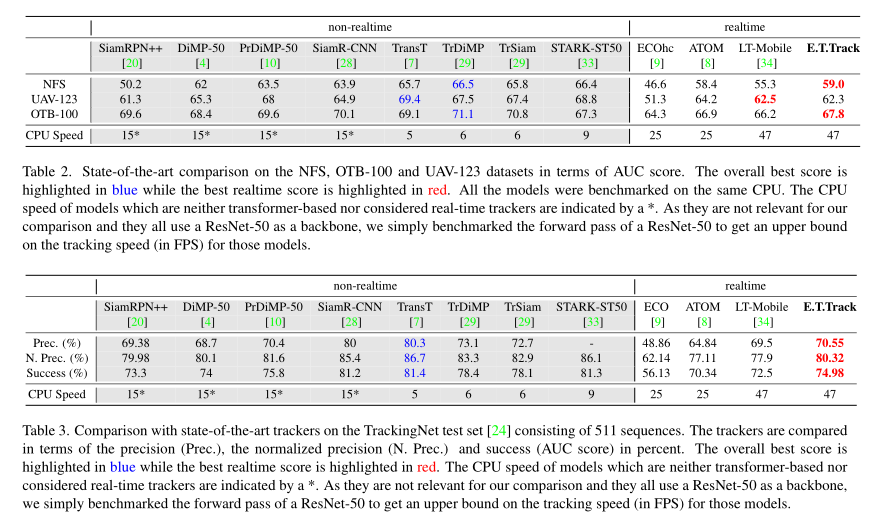
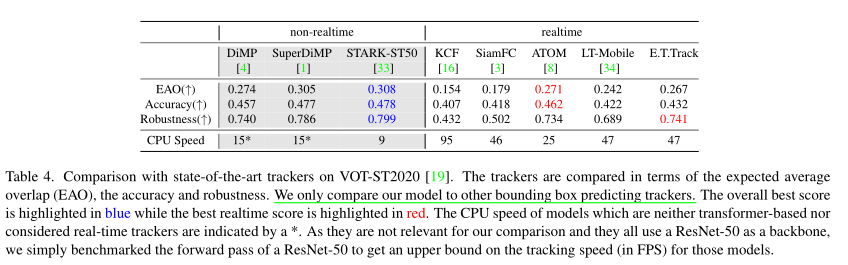
本文对transformer架构进行轻量化,提出了一种高效的Exemplar Transformer来替代卷积。E.T.Track在CPU上速度达到47FPS,比其他基于transformer的跟踪器快8倍,作者称这是目前唯一的实时transformer-based的跟踪器。
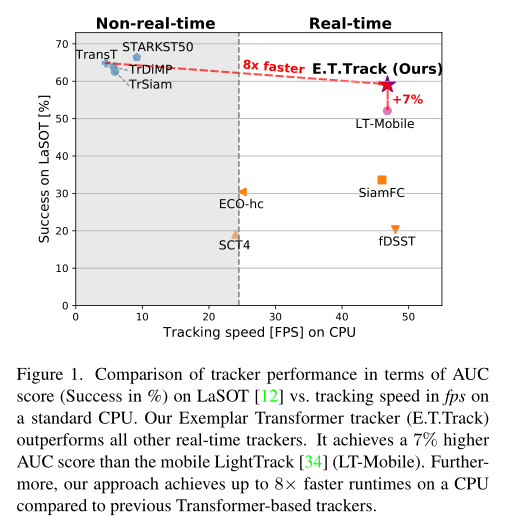
Exemplar Transformers
transformer中self-attention计算如公式2:

Q,K的序列长度均为图像尺寸,公式2计算复杂度为图像尺寸的平方,这样带来较大计算负担。作者认为,对所有特征之间的关联在机器翻译中是必要的,但是在视觉任务中是不必要的。因为机器翻译中每个特征都代表一个特定的单词或标记,而视觉任务中相邻的空间通常表示相同的物体。因此在视觉任务中,可以减少特征向量的数量,构建一个更粗略更具描述性的视觉表达,从而显著降低计算复杂度。
作者首先提出了两个假设:
- 一个小的exemplar value集合可以在一个数据集之间共享;
- 一个粗略的查询具有足够的描述性来利用这些exemplar value。
为此,作者在构建query时首先将输入特征图$X \in \mathbb{R}^{H \times W \times C}$通过平均池化压缩成空间维度为S的大小,再经过线性映射得到Q。
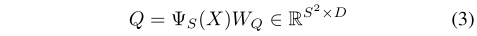
其中S=1,即将query映射成一个向量,这样可以使效率最大化。作者认为对于单目标跟踪,一个查询就足够了。
对于Key,作者学习了一小组捕获数据集信息的范例表示,而不是一个细粒度的特征映射和仅仅依赖于样本内部的关系。 Exemplar keys可以表示成$K=\hat{W}_K \in \mathbb{R}^{E \times D} $,数量从HW降为E。这个Key与输入特征是无关的,是从整个训练数据集中学习出来的一个变量。
对于Value,采用卷积操作在局部层面进行操作。
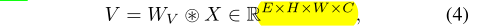
其中$W_V \in \mathbb{R}^{E \times K \times K}$。整个exemplar attention可以表示为:

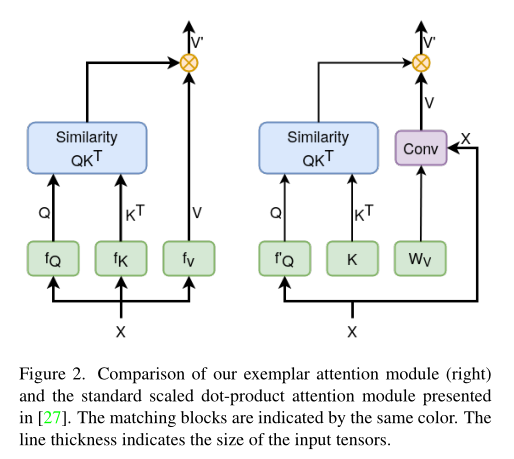
exemplar attention和传统的self-attention对比如图2和3所示,本文方法利用卷积处理局部特征,利用相似性度量处理全局特征。
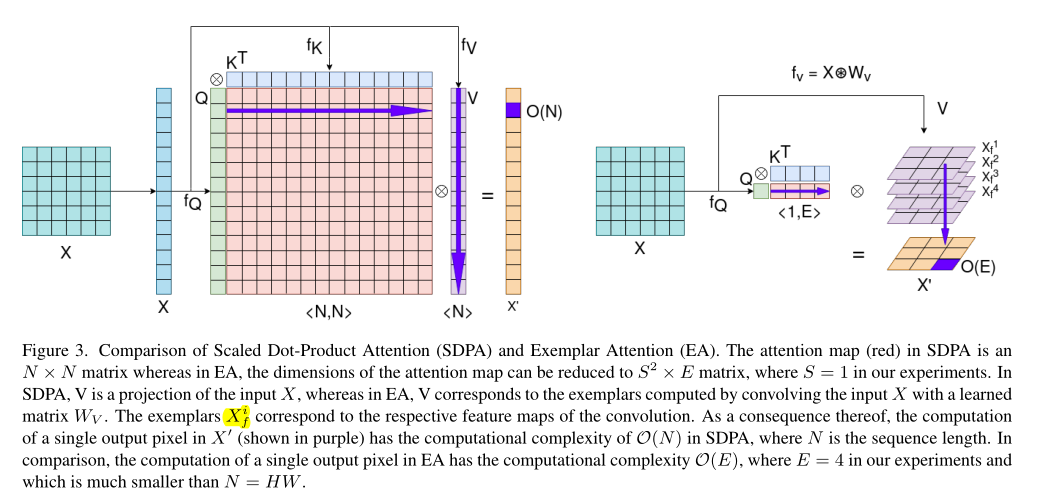
计算复杂度分析如表1所示,其中Key的数量E=4,所以Exemplar Attention的计算量和卷积是同一个量级的。

E.T.Track Architecture
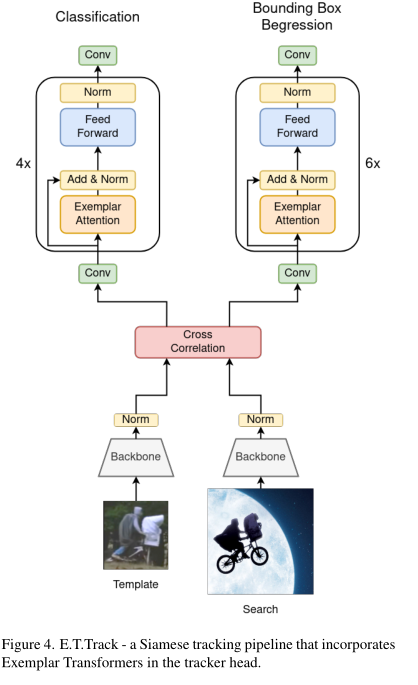
上述提出的Exemplar Transformer layer可以作为卷积的替代,作者将LightTrack的预测头分支所有卷积换成了Exemplar Transformer,构建新的跟踪器E.T.Track如图4所示。
实验
FEAR

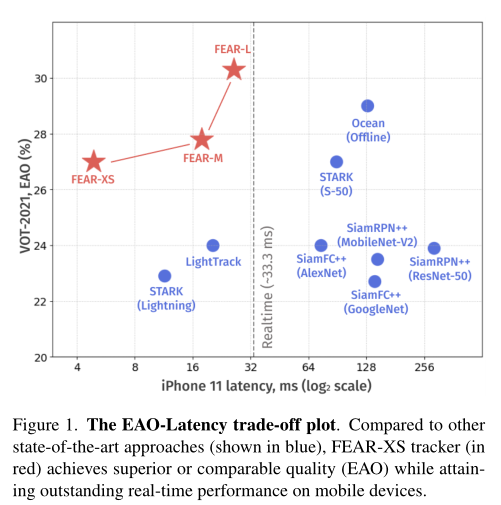
本文的目的是设计快速、高效、准确、鲁棒的跟踪器,提出两个轻量化模型,dual-template module和pixel-wise fusion block。前者使用一个可学习的参数集成了时域信息,而后者使用更少的参数编码了更有判别性的特征。使用复杂的backbone,本文方法FEAR-M和FEAR-L在速度和精度上超过大多数算法;而使用轻量backbone的版本FEAR-XS比目前的Siamese跟踪器快10倍以上的跟踪速度,同时保持接近的精度。FEAR-XS比LightTrack小2.4倍,快4.3倍,且具有更高的精度。此外,本文引入能耗和速度来扩展模型效率的定义。
方法
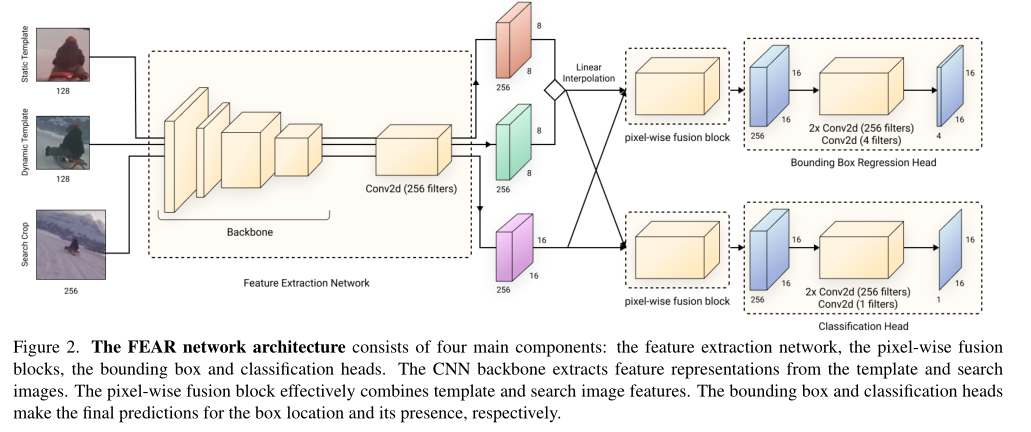
整体方法如图2所示,跟经典siamese方法的差别在于输入增加了一个动态模板,将静态和动态模板进行线性插值后再与搜索特征进行融合。
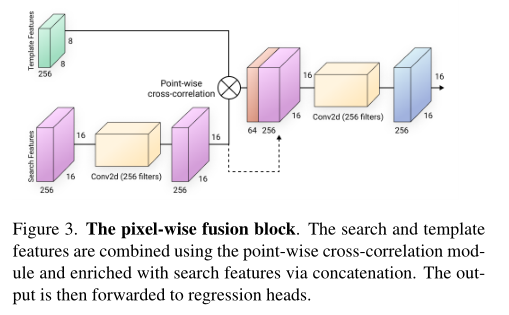
特征提取部分使用轻量的FBNet,特征融合部分设计了像素级别的融合,如图3所示,这个和PGNet,CGACD等方法的操作是一样的。
Dynamic Template Update
初始模板$F_T$和动态模板$F_d$通过可学习的参数$\omega$进行线性融合。
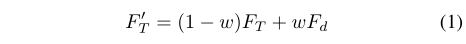
动态模板的选择如图4所示
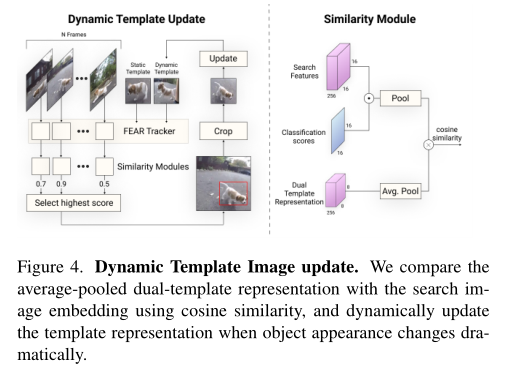
将搜索特征与分类分数相乘后池化得到向量$e_s$,动态模板进行池化得到向量$e_t$,计算二者的余弦相似度。推理阶段从每N个历史搜索帧中选择相似度最大的帧裁剪更新动态模板。训练时还额外增加了负样本$e_T$构建三元损失。
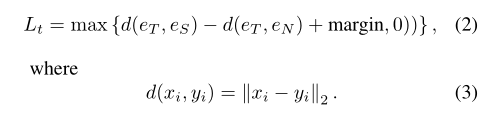
实验
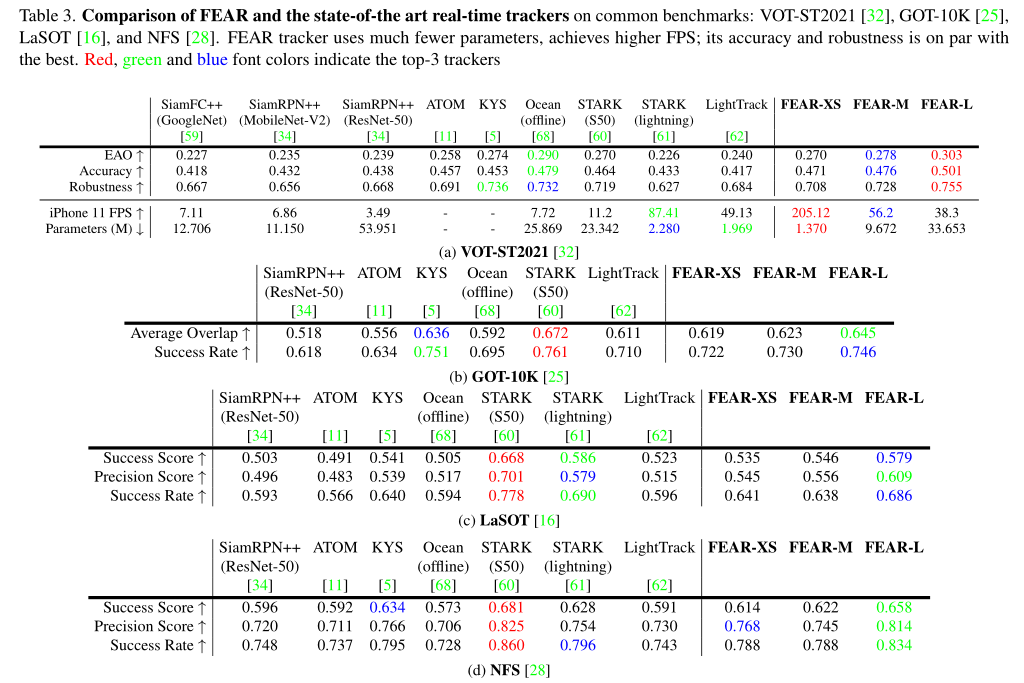
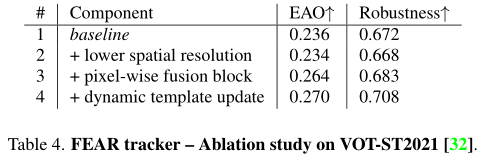
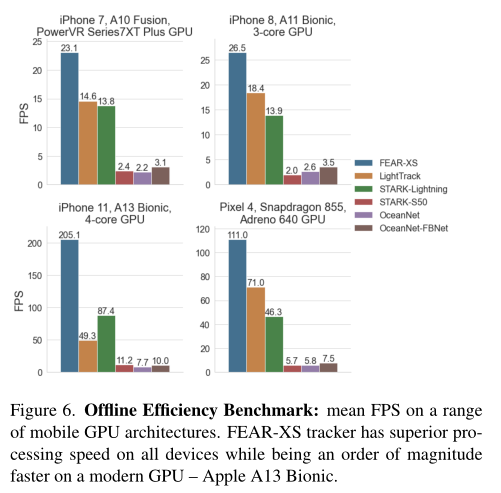
实验除了常规的benchmark性能测试还专门做了效率分析。作者引入了FEAR Benchmark来评估跟踪算法对移动设备电池和热状态的影响,以及随着时间的推移对处理速度的影响。如图5所示,随着运行时间的增加,其他算法均出现了速度下降、电量下降,温度升高的现象,但本文的FEAR-XS在这些指标上均能保持稳定(高速、耗电少、温度低)。

速度上在多款手机处理器上均大幅超过了LightTrack。