SparseTT: Visual Tracking with Sparse Transformers

Transformer中自注意力的全局视角导致主要信息(如搜索区域中的目标)聚焦不足,而次要信息(如搜索区域中的背景)聚焦过度,使前景和背景的区分变得模糊,从而降低了跟踪性能。简单来说就是和每一个点计算注意力,导致背景部分占据了过大的权重,一定程度上削弱了目标。本文使用稀疏注意力缓解这一问题,来突出搜索区域中的潜在目标。
Motivation
- 自注意力缺乏对搜索区域中最相关信息的关注,因此很容易被背景分散注意力
- 设计稀疏注意力关注搜索区域中最相关的信息
- 设计双头预测器,提高分类和回归的精度
- 稀疏注意力更容易收敛,训练时间相比TransT减少了75%
Method

标准的三段结构,特征提取,目标聚焦网络和双头预测器。
目标聚焦网络

目标聚焦网络是encoder-decoder架构,encoder输入模板特征,decoder输入搜索特征。其中encoder重要但非必要,后续实验会证明。而本文的核心创新在于decoder橙色部分的稀疏多头注意力Sparse Multi-Head Self-Attention。
朴素MSA中,注意力特征的每个像素值都是由输入特征的所有像素值来计算的,这使得前景边缘区域变得模糊。本文提出的稀疏方法中,注意力特征的每个像素值都只由与其最相似的K个像素值决定,这使得前景更加集中,前景边缘区域更加具有分辨力。
具体实现如图4中间所示,首先计算query和key的相似度矩阵,然后仅使用softmax函数对相似矩阵每行的K个最大元素进行归一化,其他元素置0。最后将相似度矩阵和value相乘,得到最终结果。图4最右边展示了两种注意力归一ecise RoI-Pooling化的区别,朴素点积注意力放大了相对较小的相似权重,这使得输出特征容易受到噪声和背景干扰的影响。然而,稀疏缩放点积注意力可以显著缓解这个问题。

双头预测器
对于分类和回归,均同时使用2层FC层和L个卷积层来预测。
推理阶段,对于分类任务,融合FC头和卷积头的分类分数;对于回归任务,只取卷积头输出的预测偏移量。
Experiments
在4张2080ti上训练60个小时,相比TransT在同等硬件下训练10天。
Ablation Study
编码器数量:即使不使用编码器效果依然很好,编码器数量过多导致过拟合。最佳数量为2

解码器数量:最佳数量为2

SMSA中的稀疏度K:最佳数量为32

SOTA Comparison
LaSOT

Got10k

OTB UAV

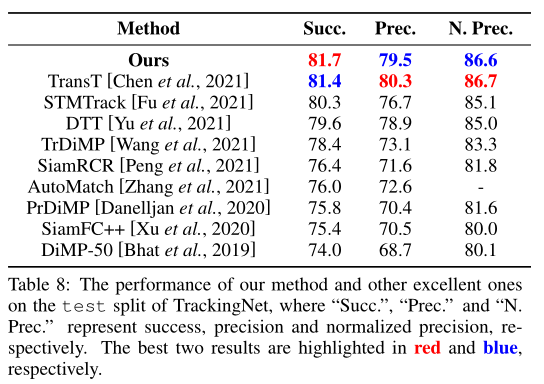
TrackingNet