Transformer Tracking with Cyclic Shifting Window Attention

具有循环移位窗口注意力
Motivation
问题:现在基于transformer的跟踪器都采用逐像素的attention,破坏了目标的完整性,并丢失了像素间的相对位置信息。(感觉就是说attention没有像卷积那样的局部归纳偏置)
创新点:
- multi-scale cyclic shifting window attention,将注意力机制从像素级提升到窗口级。(这个名字跟叠buff一样我们拆成三要素来看 :window——保留目标的完整性和相对位置关系;cyclic shifting——增加window的数量; multi-scale——在attention的多头上分别设置不同的window 大小来表示多尺度)
- 空间正则化mask,消除循环位移的边界效应影响
- 计算优化策略减小计算冗余

Method

Multi-Scale Cyclic Shifting Window Attention

论文描述的比较复杂,我这里就简化一下,按照开始提到的三要素来介绍:
构建window序列 经过特征提取后,将维度为$H \times W \times d$的特征按窗口大小 $r$ reshape成一个窗口序列$H/r \times W/r \times r \times r \times d$,然后把窗口看成一个整体,将窗口中的每个空间位置拉平到通道维度,变成$(H/r \times W/r) \times (r \times r \times d)$,相当于有 $H/r \times W/r$ 个维度为 $r \times r \times d$ 的向量。对模板和搜索特征做相同的操作并且将两个窗口序列拼接。
multi-scale 通过在attention的多头上分别设置不同的窗口大小来表示多尺度。
cyclic shifting 设计循环位移主要有两个动机:
- window attention 减少了序列的个数,即从$H \times W$下降到$H/r \times W/r$,使得attention map的分辨率降低,相似性分数比较粗糙。
- 多头注意力在每个头设置了不同的窗口大小,使每个头的尺寸$H/r \times W/r$不一样,难以融合。
因此作者设计了循环位移增加窗口的数量,参照相关滤波中的循环位移,将窗口沿着x和y方向分别每次移动一个像素,最远移动距离是$r$,即一个$r\times r$的窗口经过循环位移后产生$r^2$个同样大小的窗口样本。

经过循环位移后,得到的窗口序列维度为$(H/r \times W/r \times \textcolor{Red}{r \times r}) \times (\textcolor{Green}{r \times r} \times d)$,其中$\textcolor{Red}{r \times r}$表示循环位移窗口数量,$\textcolor{Green}{r \times r}$表示窗口的大小。然后拿它去做标准的multi-head attention。
Spatially regularized attention mask
类似相关滤波中的空间正则化,用于抑制循环位移边界效应带来的性能下降,正则化mask直接叠加到attention map上。
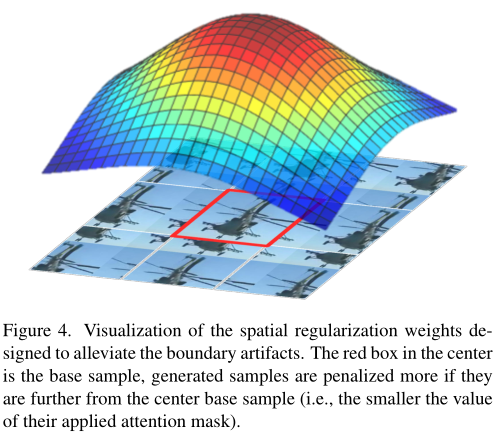
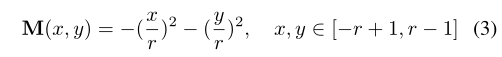
Computational optimization
循环移位操作极大地增加了计算冗余,提出了3种优化策略提升计算效率:
- query不使用循环位移:此时Q的维度保持$(H/r \times W/r) \times (\textcolor{Green}{r \times r} \times d)$,而K,V的维度是$(H/r \times W/r \times \textcolor{Red}{r \times r}) \times (\textcolor{Green}{r \times r} \times d)$。这样每个head计算$Attention(Q, K, V)$后的维度是$(H/r \times W/r) \times (\textcolor{Green}{r \times r} \times d)$,多头融合时似乎又面临尺度不一致的问题。在代码实现中,通过两次
view将$\textcolor{Green}{r \times r}$提到前面又变回了$H \times W \times d$,然后再进行多头融合。这么看来,不管有没有循环位移,都可以进行多头融合。那么循环位移的唯一目的就是增加窗口数量,获得更精细的注意力相似图。
1 | t1 = merge_feat[:, :first_L, :] # (b, first_L, window_size*window_size*c) |
移位周期减半:将循环位移的生成的的样本数量从$(2r-1)^2$减半变成$r^2$,主要是为了避免重复样本。比如一个一维数组[1,2,3,4,5],将其向左位移4次[5,1,2,3,4]和向右位移1次[5,1,2,3,4],其结果是一样的,所以减半了位移次数(向左和向右都只位移2次)。本博文都是按 $r^2$ 的样本数量来描述。
编程技巧:使用矩阵坐标来进行循环移位,而不是对矩阵进行直接平移。
和Swin Transformer差异
本文和Swin Transformer都使用了位移和窗口两个概念,主要有三点差异:
| Swin Transformer | CSWinTT | |
|---|---|---|
| (1) 注意力应用 | 计算每个窗口内部的像素注意力。 | 将每个窗口看作一个整体,计算窗口间的注意力。 |
| (2) 多尺度策略 | 每层用同样大小的窗口,分层合并窗口,在更深的层得到更大的窗口 | 不同的注意力头使用不同的窗口尺寸 |
| (3) 窗口位移 | 移位整个特征图,在不同窗口之间交换信息和提供连接 | 在每个窗口中应用独立的循环位移。 每个窗口根据其尺寸移位多次。 |
Experiments


Ablation Study
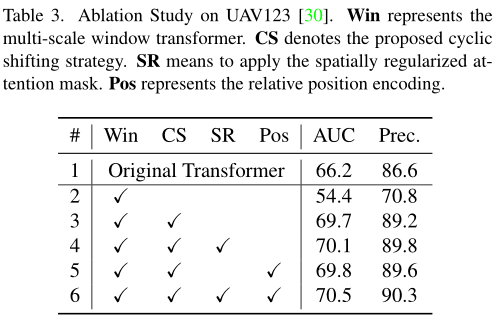
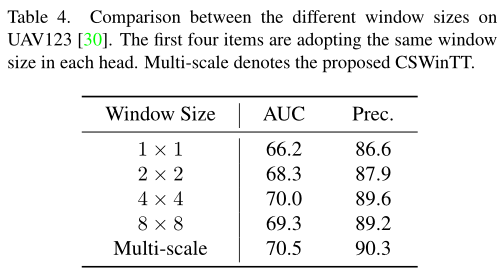
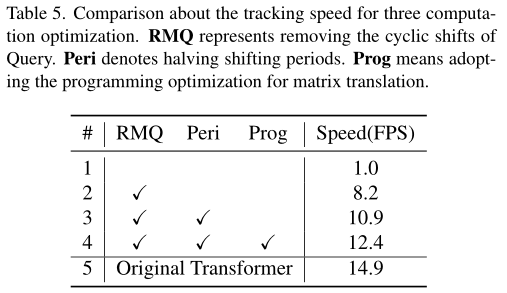
本文提出的三个优化策略虽然大幅提升了速度,但是依然存在计算冗余,主要是循环位移的窗口内依然有很多重复的pixel计算。
