AiATrack: Attention in Attention for Transformer Visual Tracking

提出了一个通用的特征提取和信息传递模块(i.e. AiA),一定程度上解决了attention机制中key和query单独匹配之后的correlation map中存在噪声和模糊权值的问题,进一步挖掘了Transformer tracker的潜力。在此基础上,作者设计的高效视频目标跟踪框架(AiATrack)在6个主流benchmark上均取得了SOTA的性能。
引言

当前的Transformer attention通过点积独立地计算每对query-key对的相关性(correlation),而忽略了来自其他query-key对之间的联系。这可能导致模型易受不完美的特征表示或背景干扰的影响引入错误的相关性。如图1右半部分中绿色节点红线部分的关联是错误的,关联到其他目标上了。单看红线连接的两个局部特征确实很相似,但旁边的棕色点节点并没有与干扰物建立关联,如果能结合这一信息就能消除错误关联。
根据上述分析,作者认为某些query-key对之间的关联应该存在一致性,比如一个key与一个query有很高的相关性,那么它相邻的一些key也会与该query有相对较高的相关性,否则这个相关性可能就是噪声。因此提出了一个attention in attention (AiA) 模块,通过挖掘相关向量的一致性来refine注意力(相关性)响应图。具体来说,就是在attention模块中内嵌了一个inner attention,将query和key相乘得到的注意力图作为输入,生成新的q,k,v再做一次attention,来增强合理的query-key对的相关性并抑制错误的query-key对的相关性。因为是直接改进attention,因此AiA可以同时嵌入特征提取的self-attention和特征匹配的cross-attention中(图1左半部分),提升跟踪性能。
本文在此基础上提出了一个高效的长短时跟踪框架来处理时域信息。大体就是构建了长时和短时的参考图同时用于跟踪,感觉是继承了马超老师(本文作者之一)LCT的思想。
本文的主要贡献如下:
- 提出AiA模块减少传统注意机制中的噪声和模糊性,并显著提高跟踪性能;
- 提出一个长短时的跟踪框架,包含特征复用,目标-背景编码等操作来高效利用时域信息;
- 6个benchmark的实验结果,性能超过stark,速度38fps。
方法
Attention in Attention

传统的attention计算如下:

上面已经分析过了,这样得到的相关图(correlation map)$M=\frac{QK^T}{\sqrt{C} } \in \mathbb{R}^{HW \times HW} $是独立计算每对query-key之间的相关性的,存在噪声和模糊。而通常来说,若一个key与一个query有很高的相关性,那么它相邻的一些key也会与该query有相对较高的相关性,否则这个相关性可能就是噪声。为了实现这一目的,作者提出了AiA,如图2红色部分所示,直观上看就是在attention模块中内嵌了一个inner attention。
AiA将correlation map $M$作为输入,其中每一列都表示一个key与所有query之间的相关性,把它当成一个相关向量(correlation vector),列数就表示有多少个这样的相关向量,这样就得到了一个相关向量序列。然后通过一个新的inner attention构建每个key对应的相关向量之间的关系,如果两个相关向量具有一致性,则认为其中的query-key的相关性是合理的,应该增强;反之则被视作需要抑制的噪声。最后通过一个残差映射将这个一致性关系叠加到原始的相关图上。
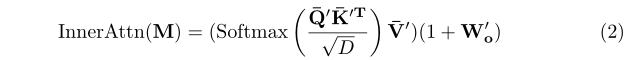
这里的$Q’,K’,V’$都是由correlation map $M$生成的,其中$Q’,K’$经过FC降维成$HW \times D$,$V’$的维度是$HW \times HW$。添加了AiA后的attention可以表示为:
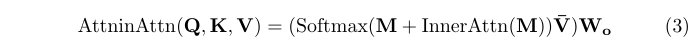
图4展示AiA 矫正前后的相关向量可视化结果,可以观察到,AiA模块有效地抑制了错误的相关性,并增强了正确的相关性。

Proposed Framework

在AiA的基础上,本文提出了一个跟踪框架AiATrack。这是一个长短时框架,初始帧作为长时参考图,若干张中间帧的聚合作为短时参考图(训练时只用1帧,测试时用了3帧)。长时参考图是可靠的,用于稳定跟踪;而短时参考图可以适应一些外观和背景的剧烈变化,这种思想在跟踪中很常见。参考图和搜索图经过特征提取和编码器的self-attention强化后,使用解码器的cross-attention对二者进行特征交互,最后送入预测头输出结果。
Target-Background Embeddings 因为输入的参考图同时包含目标和背景,需要一种手段来区分二者同时保留上下文信息。作者这里设计了一种目标-背景编码,分别为目标和背景设置一个可学习的编码。然后在目标区域放置目标编码$\varepsilon^{tgt} \in \mathbb{R}^C$,背景区域放置背景编码$\varepsilon^{bg} \in \mathbb{R}^C$,生成一个target-background embedding map $\varepsilon \in \mathbb{R}^{HW \times C}$,将其与参考特征叠加一起送入decoder。这个有点类似目标-背景mask,但是并没有完全丢弃背景信息,而是保留了目标和背景的上下文。

Prediction Heads 预测头采用了stark的角点预测,还额外增加了一个ATOM的IOU预测分支,用于预测框的准确性,评估是否用当前搜索帧更新短时参考序列。若IOU大于阈值,则将编码器输出特征保存起来作为新的短时参考特征。注意这里更新的是特征而不是原始图像,这种特征复用更加高效。一并保存的还有根据搜索帧预测结果生成的target-background embedding map。
Experiments
Results and Comparisons



Ablation Studies
消融实验表3中第一部分验证Target-Background Embeddings的效果比使用目标-背景mask和什么都不用要好,证明这个方法既可以区分目标和背景区域,同时保留了上下文信息。第二部分验证了长短时架构是有提升的,并且应该分离使用,混在一起会导致不可靠的短时模板污染长时模板。第三部分验证了AiA模块在self-attention 和cross-attention都是有用的。

表4证明了AiA模块的提升不是因为引入了更多参数。作者尝试简单堆叠原始attention(cascade),并没有提升。证明还是需要对相关图进行矫正,而作者又尝试了使用卷积来矫正,有提升但不如attention效果好。主要由于卷积是固定的局部感受野,而attention可以构建动态的全局感受野,更加灵活。
